
When a single brand appears as “Nike,” “NIKE,” “nike inc,” and “Nike, Inc.” across your product catalog, analytics platforms, and marketplace listings, you’re not just looking at formatting inconsistencies. You’re looking at revenue leakage, fractured customer intelligence, and operational drag. Brand name normalization rules are the bridge between how customers search for brands and how your systems recognize them.
But here’s what most guides miss: normalization isn’t primarily a data-cleaning exercise. It’s a governance strategy with downstream effects on supply chain visibility, paid search efficiency, and omnichannel attribution.
This guide moves beyond basic string manipulation to deliver a production-grade framework for brand name normalization—one that scales with enterprise complexity, accommodates global nuances, and transforms standardization from a technical chore into a competitive asset.
Why Standard Brand Name Normalization Rules Fail at Scale
Most organizations begin brand name normalization with the best intentions. They create reference tables. They strip punctuation. They apply title case. Then, six months later, “3M” and “Three M” are both in the system again.
The breakdown isn’t caused by technology. It’s structural.
Effective brand name normalization rules don’t just clean data—they prevent inconsistency at the source. They account for how different systems store, display, and search brand strings differently. And they recognize that a brand name traveling through an ERP system, a PIM, and a marketplace feed follows three different sets of formatting constraints.
The Hidden Complexity Behind “Simple” Normalization
Consider a brand like L’Occitane en Provence.
-
Your ERP might truncate it to “LOCCITANE”
-
Your e-commerce platform accepts the apostrophe but strips the space
-
Your marketplace feed rejects non-ASCII characters entirely
-
Your analytics tool sees “L’Occitane,” “LOccitane,” and “L Occitane” as distinct entities
No single normalization rule applied after the fact can reconcile these inputs cleanly. This is why brand name normalization rules must be system-aware, not just string-aware.
Core Components of Enterprise-Grade Brand Name Normalization Rules

Rather than a one-size-fits-all rule set, mature organizations implement layered normalization logic. Each layer addresses a distinct failure point in the brand data lifecycle.
Layer 1 – Ingestion Normalization
Block poor-quality data at the point of entry. Before any brand string enters your systems, apply:
- Character-set mapping: Convert non-ASCII characters to their nearest ASCII equivalent (é → e, ü → u) unless your brand guidelines require the original diacritics for display purposes. Store both versions—the normalized string for matching, the original for presentation.
- Case enforcement: Reject or autocorrect mixed-case entries at the form level. If your canonical format is “Apple,” don’t allow “aPpLe” into the database.
- Whitespace compression: Replace multiple spaces, non-breaking spaces, and tab characters with a single standard space.
Layer 2 – Logical Equivalence Rules
This layer handles abbreviations, legal suffixes, and corporate designators.
Suffix standardization:
-
“Inc,” “Inc.”, “Incorporated” → normalize to “Inc”
-
“LLC,” “L.L.C.”, “Limited Liability Company” → normalize to “LLC”
-
“Co,” “Company” → normalize per brand-specific rule
- Corporate designator positioning: Different systems may record the brand as “Johnson & Johnson” in one database and “Johnson and Johnson” in another. Determine whether ampersands expand to “and” or remain symbols, then apply consistently.
- Trademark and registered symbols: Strip ® and ™ from matching logic, but preserve them in customer-facing contexts where legally required.
Layer 3 – Contextual Normalization
A brand name never functions independently of its context. Their canonical form often depends on where they appear.
- Marketplace-specific normalization: Amazon may restrict parentheses; Walmart may restrict certain symbols. Your normalization rules should map brand names to the most complete representation each platform allows, not force identical strings across every channel.
- Regulatory-context normalization: Pharmaceutical and financial brands often require full legal names in compliance documentation but abbreviated forms in consumer interfaces. Store both, and apply rules based on destination context.
Building a Brand Name Normalization Rule Engine
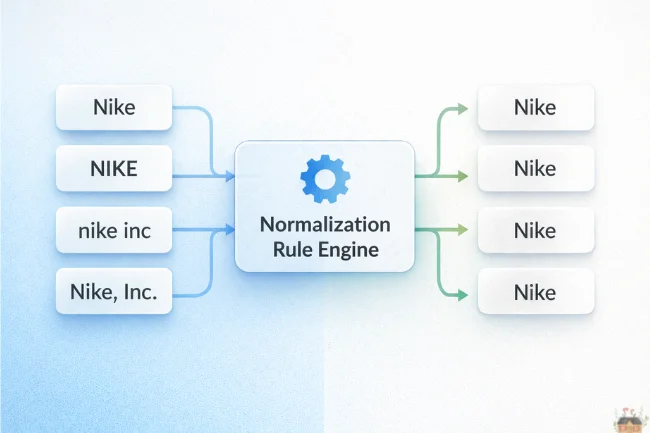
Organizations that treat normalization as a one-time cleanup project inevitably regress. The alternative is a persistent rule engine that evaluates every brand string—incoming and existing—against dynamic, version-controlled policies.
Rule Hierarchy and Conflict Resolution
Not all normalization rules carry equal weight. Establish a hierarchy:
-
Exact-match overrides (highest priority): “Google” should never normalize to “GOOGLE INC”
-
Brand-specific rules: “Mattel, Inc.” → “Mattel”
-
Pattern-based rules: Convert ALL CAPS to title case unless brand is explicitly acronym-based (IBM, 3M, HGTV)
-
Global formatting rules: Strip trailing punctuation, remove duplicate spaces
When conflicts arise (e.g., a brand-specific rule contradicts a global rule), the higher-priority rule prevails.
Exception Management Infrastructure
Every normalization rule generates exceptions. Build mechanisms to:
- Flag ambiguous cases: If “National” could refer to “National Geographic,” “National Instruments,” or “National Car Rental,” route to human review rather than applying a default rule.
- Monitor rule performance: Track how frequently each rule fires and how often its outputs require manual correction. Low-confidence rules degrade overall data quality.
- Version control: Brand names change. When “Philip Morris” becomes “Altria,” your normalization rules must update systematically, not reactively.
Advanced Techniques for Complex Brand Portfolios
Organizations managing thousands of brands—distributors, marketplaces, enterprise retailers—face normalization challenges that simple lookup tables cannot solve.
Fuzzy Matching with Business Context
Levenshtein distance and soundex algorithms identify likely misspellings. However, they are prone to overmatching. Enhance fuzzy matching with:
- Category context: A brand string containing “dairy” is more likely to be “Land O’Lakes” than “Land of Lakes” if the product category is butter.
- Vendor reference data: Cross-reference normalized brands against GS1 Global Product Classification or your suppliers’ official brand registries.
- Historical correction patterns: If users consistently correct “Nestle” to “Nestlé,” train your system to apply this correction automatically.
Sub-Brand and Variant Relationship Modeling
“Apple iPhone 15 Pro Max” is not a brand normalization failure. It’s a brand-variant relationship.
Design normalization rules that:
- Extract rather than flatten: Store the brand (“Apple”), product line (“iPhone”), model (“15”), and tier (“Pro Max”) in separate fields before normalization. Then normalize each component independently.
- Preserve hierarchy: Canonical brand form applies to the brand component only. Don’t normalize “Sony PlayStation” to “Sony” simply because “Sony” is the parent brand.
Measuring Brand Name Normalization Effectiveness
If you cannot measure normalization, you cannot sustain it. Shift the focus from “percentage of records normalized” to metrics that reflect real business impact.
Operational Metrics
- Deduplication rate: How many previously distinct brand records merged post-normalization?
- Search zero-result rate: Before normalization, how many internal brand searches returned nothing? After normalization, what’s the reduction?
- Listing suppression rate: On marketplaces, how many listings were hidden due to brand attribute mismatches? Normalization is expected to decrease these occurrences.
Commercial Metrics
- Attribution accuracy: What percentage of sales can you confidently attribute to the correct brand? Improved normalization consolidates fragmented brand reporting.
- Procurement matching: For distributor operations, does your purchase order system correctly match incoming goods to the brand master record? Normalization directly affects inventory accuracy.
Brand Name Normalization in AI and LLM Environments
As organizations deploy generative AI for product copy, customer service, and internal search, brand name normalization rules must adapt.
- Training data consistency: LLMs trained on inconsistently formatted brand names learn inconsistent patterns. Pre-normalize historical brand data before feeding it into AI training pipelines.
- Output enforcement: AI-generated product titles or descriptions should pass through post-processing normalization rules before publication.
- Entity extraction: When extracting brand mentions from unstructured text, apply normalization after extraction but before storage.
Governance Models That Prevent Normalization Decay
The most sophisticated normalization rule set is worthless without organizational follow-through.
Federated Stewardship
Rather than centralizing all normalization decisions in IT or data engineering, distribute ownership:
- Brand managers maintain canonical name definitions and approve exceptions
- Merchandising teams flag marketplace-specific normalization conflicts
- Supply chain teams validate that supplier brand representations match internal standards
- Data engineers implement and monitor rule performance
Audit Cadence and Triggers
Schedule proactive audits, but also trigger reactive audits when:
-
A new supplier or brand partner is onboarded
-
A legacy system is migrated or retired
-
A major marketplace updates its brand attribute requirements
-
A brand undergoes rebranding or acquisition
Implementation Roadmap for Brand Name Normalization Rules
Phase 1: Discovery and Inventory (Weeks 1-3)
Catalog every system that stores or transmits brand names. Document each system’s technical constraints, current brand name representations, and normalization capabilities.
Phase 2: Rule Drafting and Socialization (Weeks 4-6)
Draft tiered normalization rules. Circulate to brand, merchandising, and compliance stakeholders. Address conflicts prior to rollout.
Phase 3: Pilot Deployment (Weeks 7-10)
Select one brand family or one system as a pilot. Implement rules, measure impact, and refine based on findings.
Phase 4: Phased Rollout (Weeks 11-20)
Expand to additional systems and brands. Prioritize high-volume, high-impact brand names first.
Phase 5: Monitoring and Maintenance (Ongoing)
Deploy exception dashboards. Conduct rule reviews on a quarterly basis. Build normalization competency into onboarding for relevant roles.
FAQs About Brand Name Normalization Rules
1- Should we normalize customer-entered brand names in reviews and surveys?
For display purposes, no—preserve the customer’s original input. For analytics, normalize to enable accurate brand sentiment aggregation.
2- How do we handle brand names that are also common words?
“Apple,” “Amazon,” “Shell.” Rely on context signals—product category, vendor ID, GTIN association—rather than attempting normalization based on the brand string alone.
3- What’s the difference between brand name normalization and brand name validation?
Validation checks whether a brand name exists in your approved brand master. Normalization reformats how it appears. Both are necessary, and they should operate sequentially—validate first, then normalize.
4- Can machine learning replace rule-based normalization?
Not entirely. ML excels at pattern detection and fuzzy matching, but rule-based systems provide deterministic, auditable, and legally defensible normalization decisions. The most robust implementations use ML to suggest normalization candidates and rule-based systems to apply them.
The Strategic Case for Brand Name Normalization Rules
Organizations that master brand name normalization rules don’t just have cleaner data. They have a faster time-to-market because new products aren’t delayed by brand attribute mismatches. They have a higher marketplace search ranking because consistent brand formatting signals authority to platform algorithms. They have more reliable supply chain visibility because brand representations align between purchase orders, invoices, and inventory records.
Normalization is not about removing character variations. It’s about eliminating uncertainty. And in omnichannel commerce, ambiguity is the hidden tax on every transaction.
The objective isn’t absolute uniformity. The goal is predictable, intentional variation—applied consistently, governed responsibly, and optimized continuously.
That is the difference between brand name normalization as data hygiene and brand name normalization as strategic capability.
For broader information, visit Wellbeing Makeover
Alex Carter is a writer with 10+ years of experience across tech, business, travel, health, and lifestyle. With a keen eye for trends, Alex offers expert insights into emerging technologies, business strategies, wellness, and fashion. His diverse expertise helps readers navigate modern life with practical advice and fresh perspectives.